Playing with AI on the Pi 5!
With all the hype around the latest AI model from China called DeepSeek, we gave it a go running on a Raspberry Pi 5 using Ollama with some pleasing results.


That's right, now you can play with AI on your Raspberry Pi 5 and you don't even need an AI HAT! In fact, if you do have an AI HAT it’s not going to help when you want to try out LLMs (Large Language Models) like ChatGPT, because the HAT is designed for PyTorch and Tensor operations and is tuned for image processing only. So there’s no need to spend the extra cash to have a play! Better still, it’s really, really easy to install and get started.
With the Chinese recently releasing DeepSeek, which they claim to be a super efficient AI LLM, I thought I'd give it a go and see what happens. I wasn't holding my breath and didn't expect much as it’s going to be using the Pi’s CPU which isn’t super beefy. However, I was pleasantly surprised. It’s not fast, but it ran (for free), giving me private AI. No putting my questions into a website and having my sessions recorded - this all ran locally, in the privacy of my home lab.

In order to run AI models easily on Linux (this also works on Windows and macOS) we are going to use a program called Ollama. Think of Ollama as the docker for AI models, it pulls down the model and runs it for you already configured and ready to go. You can also manage the models - pulling, stopping and deleting them just like you would with docker container images.
Keep reading to find out how easy this is to install and please don't forget subscribe - it’ll really help attract sponsors for future projects!
Installing Ollama
This is a super simple task and just requires one line of bash to install, so open up your terminal and paste the following into it.
curl -fsSL https://ollama.com/install.sh | shOnce the script finishes you have the ability to run lots of AI models at your finger tips. You’ll need to think about memory though because in order to run a model you need to load it all into RAM. So if you pick a large model, it’s not going to fit and, depending on your Pi model, that’s going to vary. The good news is that deepseek-r1 8b fits perfectly on a Pi 5 with 8gb of ram as it only takes up about 4.9gb, so there’s RAM left over for running the OS. The 8b stands for ‘8 billion parameters’, which is the amount of reference points the model is trained on. The larger the amount of parameters, the more resources the model has to pull its answers from. The 14b model, which is the next size up, takes up 9gb so wouldn’t fit on the 8gb Pi 5 I’m using. If you want the larger model, you’ll have to get the Pi 5 16gb.
Running DeepSeek-r1 on Ollama
Yet again Ollama makes this super simple - the command bellow pulls the model down from the registry and runs it for you.
ollama run deepseek-r1:8bThe result is you are brought to the prompt and you’re ready to go!

Test question
I gave the model a go with the question “What’s the weather like in Paris this time of year?”
Here are some screenshots of the results. What’s interesting, is that you can see the reasoning the model makes before it gives you an answer. This is indicated by <think></think> tags in the output which is one of the nice features of this model compared with others where you don’t get to see the “thought” process and how they arrive at the answers given.
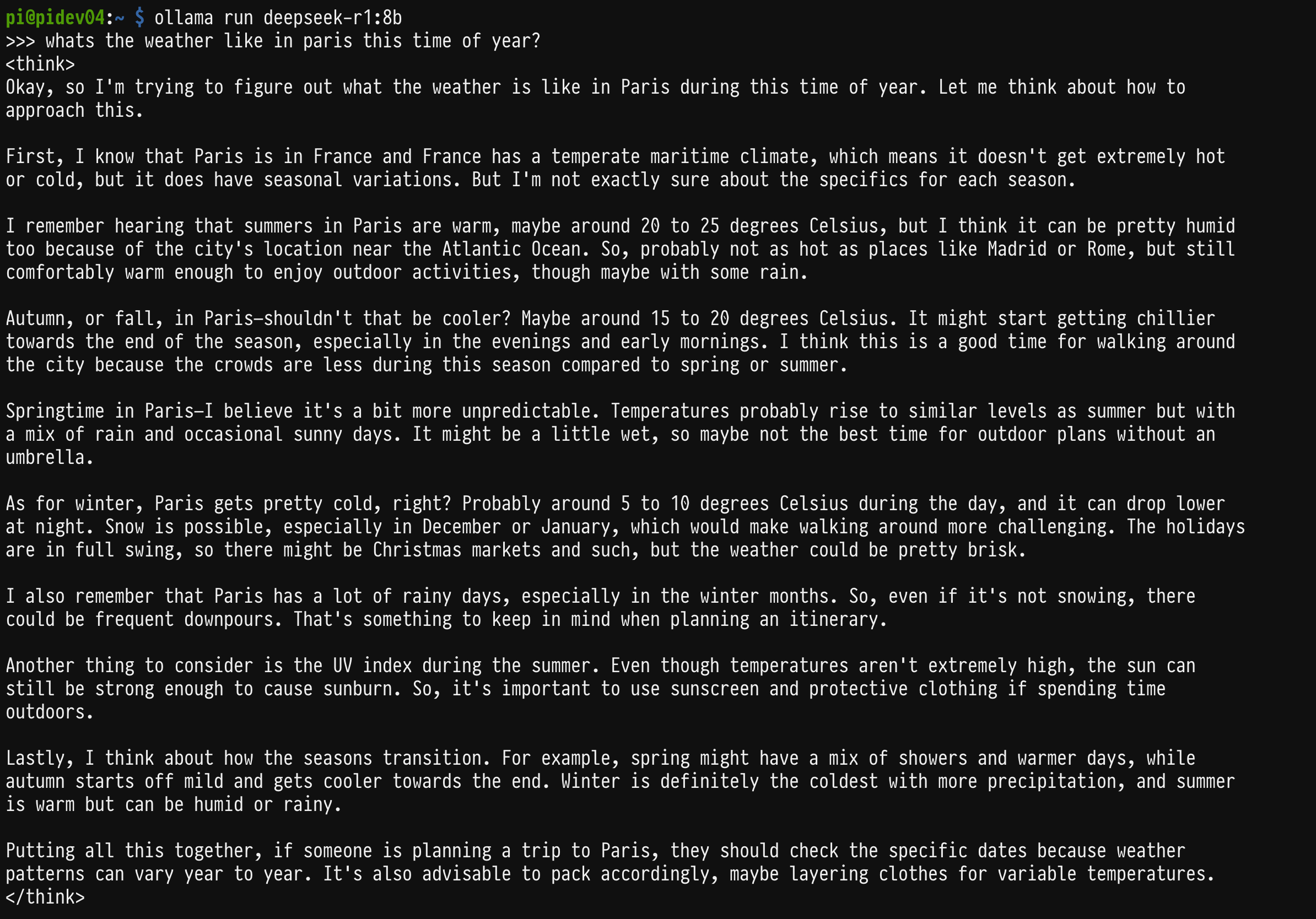

The reasoning and answer from the model
The whole process took a couple of minutes to produce the answer, so it’s not the fastest thing in the world but it did work on this modest hardware. Let’s not forget the real advantage is all the inference (thats the querying of the model) was done locally (thus privately), and for me that’s a game changer. None of my data ever left my home lab.
It’s worth saying that if you had a GPU (in the form of a graphics card) from AMD or NVIDIA, Ollama would automatically take advantage of this and the inference would be much, much quicker. Running purely on the CPU of the Pi gave me about 1.4 TOPS (terra operations per second) which is slow when compared with other GPUs, e.g. the AMD Radeon 7700, which clocks in at between 40-50 TOPS. However, the Radeon alone costs more than £400, with other graphics cards costing thousands of pounds. A Pi 5 8GB is a mere £76.80 (at time of publication) by comparison.
Other models
There are of course lots of other models you can run using Ollama, such as Llama 3, Phi-4, Gemma 2 and specialist tuned models, such as deepseek-coder, which is trained on coding data and aimed to help you write code!
You can check out all the models here on the Ollama website.
Conclusion
This isn’t going to break any speed records when running on a Pi 5’s CPU, but with more efficient models like deepseek-r1 appearing all the time, it’s getting interesting that even low-cost devices can run inference on these models. Ollama makes trying out these models really easy, in fact I’m blown away by how simple this was. I studied AI many moons ago at University and boy, was it different back then! Ollama is really democratising the access to AI.
DeepSeek is an interesting model, it’s efficient even on the Pi and that makes it usable. There’s a lot of hoohaa at the moment that it might be trained on the data from other models, and other AI companies would have you believe that’s a bad thing, but don’t let that put you off because their models were in turn trained on the text, images, music and videos we all created, so there’s an element of hypocrisy in their criticism.
Pro’s
- Inference is local (no data given over to other companies)
- You don’t have to pay a monthly subscription to an AI service
- You can experiment with different models and find the best one for you
Con’s
- It’s slow compared to services on the web unless you have a GPU attached
- You are limited by your RAM (or RAM on the graphics card)
- Some of the commercial models aren’t available
PiSource Score (for Ollama)
| Easy of Setup | Features | Ease of Use | Extendability | Total |
|---|---|---|---|---|
| 10 | 10 | 10 | 10 | 40/40 |
If you’ve enjoyed this article, please subscribe and help support more projects and testing in the future.